
Disaster recovery (DR) is one of the most important objectives in any organisation and with it, business continuity. It’s critical to understand exactly what it will take to get a business back up and running as quickly as possible when disaster strikes. While some experts see disaster recovery and cybersecurity as separate initiatives run by different teams, there’s enough correlation to make each critical to the overall effectiveness of the other. “Disaster recovery is post an event,” says Byron Horn-Botha, business unit head at Arcserve Southern Africa. “Business continuity is about ensuring an acceptable uptime and continuous uptime, so that users are not even aware when a system is down. When disaster recovery is engaged, nine times out of 10, users are affected – that’s the difference.”
BACKING UP…
What happens when your backups become compromised? One of the main reasons this happens is because businesses often put disaster recovery and backups into the same box. “These are not the same, so please don’t treat them that way,” says Bradley Knapp, a product manager at IBM Cloud. “They have generally similar goals and their goals are both good things – to protect you in the event of some sort of failure,” he says. A good example is a backup that protects an organisation from a host failure – if the system a company is running goes down, there is a backup in place. “And the data is still there. It will also protect you from some sort of malicious attack or small-scale failures,” Knapp says. A disaster recovery scenario, however, is a different kind of protection. “You want to back up all of your data – small applications, big applications, development that you’re doing. Everything should be backed up so in the event of a smaller failure, you don’t lose all of the work you’ve done. Disaster recovery is not the same thing. Disaster recovery, first of all, is about production applications,” he adds. With DR, it’s not a host failure, but an entire region failure. “Solving a DR problem can’t be done with backups and DR is not a backup of your production system. You cannot just have a DR site and assume that’s good enough,” he adds.
One of the reasons is the rise of ransomware. According to Ria Pinto, country general manager and technology leader at IBM South Africa, the average time of cybercriminals completing a ransomware attack has dropped from two months to less than four days. “In our region, Middle East and Africa, the most common method of cyberattacks (27%) used is backdoor deployments, which contribute to the $3.36 million data breach costs absorbed by South African organisations. Where businesses keep their data matters more than ever,” she says. “Organisations should not only plan to protect their data, but they should have contingency mechanisms designed to prevent or minimise data loss and business disruptions as a result of catastrophic events such as equipment failures, localised or national power outages, cyberattacks, civil emergencies, criminal attacks, and natural disasters.”
IDC research shows that infrastructure failure can cost as much as $100 000 per hour, and critical application failure costs can range from $500 000 to a million dollars per hour. “Many organisations cannot recover from such losses. More than 40% of small businesses will not reopen after experiencing such a disaster, and among those that do, an additional 25% will fail within the first year after the crisis,” says Pinto.
Knowing where to start can also present a challenge. “Often, it becomes an overthinking exercise with lots of meetings and, at the end of it all, no plan,” says Horn-Botha. Cost and resourcing can also prove to be major challenges. Gerhard Swart, Performanta’s CTO, says that without previous incidents driving the spend, it can be a struggle for organisations to obtain and justify the relevant investments.
Testing, 1-2-3, testing
In order for a business to assess its vulnerability to disasters and determine its disaster recovery needs, there are a myriad solutions, such as continuous testing in which data is placed in a sandbox to monitor its behaviour.
There are also tools that assess vulnerabilities and this space is growing, as companies are keen to know where they are vulnerable, says Horn-Botha.
“That said, with the disparate environments that most organisations have, with cloud, on-premises, SaaS, etc., there are question marks.”
Having a well-defined plan means when disaster strikes, people don’t run around pointing fingers; they know what to do and take responsibility for that.
Byron Horn-Botha, Arcserve
For Pinto, a disaster recovery plan that has not been tested cannot be relied upon. “Disaster recovery plans require constant updates based on new threat intelligence that may arise. They also must be updated and periodically reviewed as an organisation’s hardware and software assets change,” she says. “A good recovery plan should have emergency response, backup operations and recovery action procedures. Regularly updating these indicators is a sure way of ensuring that your plan is effective in an ever-changing and uncertain world.” Swart recommends developing a plan based on risk priorities. In other words, identifying the most important and at-risk digital asset.
RECOVERY READINESS
Kate Mollett, Commvault’s regional director for Africa, says that, historically, disaster recovery has focused mainly on the backup process, with admins primarily concerned with making sure that backups are completed overnight and making any necessary corrections. “However, the focus should shift to recovery readiness,” says Mollett. “This way, organisations can be confident that they are ready to protect and recover their data in the face of any disaster.” To reach a state of recovery readiness, Mollett recommends organisations undertake these five steps:
1. Create a disaster recovery plan: An effective strategy is a foundation for a full and speedy resumption of normal operations.
2. Protect: Implement layers of infrastructure protection and controls to strengthen the resiliency and security posture through advanced tools, policies, and guidelines.
3. Monitor your environment: Intelligently manage your data through a single interface to ensure data availability and business continuity across your on-premises and cloud environments.
4. Restore your data: Perform fast restores with an intact and secure data copy to quickly resume normal business operations and reduce the impact.
5. Test your plan: Frequently test to verify so that you can meet your defined SLAs for high-priority data and applications.
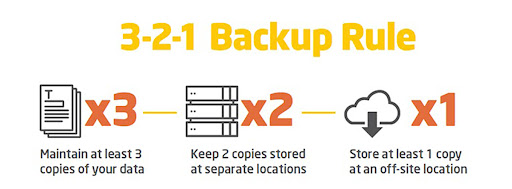
“And those DR plans should be tested regularly, varying from monthly walkthrough tests to intensive annual drills,” he says. “Since the DR solution is likely to include cloud services, adequate cloud security (such as a cloud access security broker, or service) is also very important. And never forget the 3-2-1 backup rule – no single disaster recovery site can mitigate all risks.”
A 3-2-1 methodology is when an organisation has three copies of business data on two different media types, with the third copy off-site for disaster recovery. This tried-and-tested strategy was conceived before cloud security became a thing and has since evolved into 3-2-1-1-0 and 4-3-2. In the first of these new strategies, one copy should be kept offline, or air-gapped, and there should be no errors in the data.
In the second example, there should be four copies of the data stored in three locations, such as on-prem, with an MSP, and in the cloud, and two locations are off-site.
The 3-2-1 approach is still effective, and considered by experts to be one of the best ways to begin for most types of organisations.
As Horn-Botha says: “It’s a way to ensure you recover fast and don’t disrupt users. Having a well-defined plan means when disaster strikes, people don’t run around pointing fingers; they know what to do and take responsibility for that; in other words, they’re accountable. The plan should not be a thesis, but should be succinct and understood by all stakeholders.” Effective communication and coordination during a disaster recovery scenario is vital. “However, organisations often struggle to establish clear communication channels, define roles and responsibilities, and ensure smooth coordination among different teams and stakeholders,” says Swart.
Pinto says that a comprehensive and effective disaster recovery plan necessitates the buy-in and commitment of management: “They require a commitment in terms of time, money, hardware, software, and personnel. Without these resources, an effective disaster recovery plan cannot be realised,” she says.
* Article first published on brainstorm.itweb.co.za
Share